Subtract()
Subtract operation is equivalent to except in Dataframe which is a SQL operation. This RDD operation is a wide operation. It compares both RDDs and returns values which is present in rdd1 and not present in rdd2. For better understanding, let's start with an example
Result
 From the above result we can understand the definition of subtract(). Now let's dig deeper into internals of the operation. This operation is widely depends on Partitioner and you could see subtract(...) takes HashPartitioner as one of the argument. RDD also provides another variant where it takes just another RDD as an argument yet internally applies HashPartitioner and default partition number.
From the above result we can understand the definition of subtract(). Now let's dig deeper into internals of the operation. This operation is widely depends on Partitioner and you could see subtract(...) takes HashPartitioner as one of the argument. RDD also provides another variant where it takes just another RDD as an argument yet internally applies HashPartitioner and default partition number.
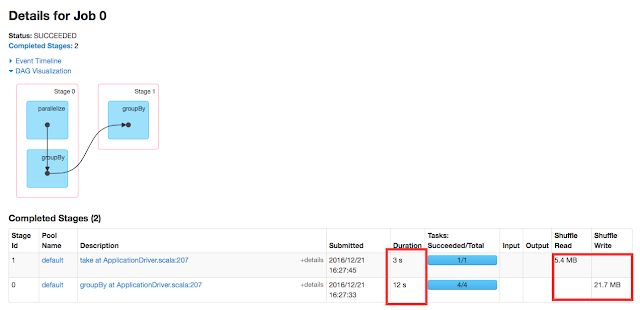
As you already know that you can apply partitioner only on RDD[(K,V)], hence this transformation is required. It converts given RDD[T] into RDD[(K,V)] where K is T and V will be always null. The outcome of this transformation is subtract block in both stage0 and stage1 on DAG screen-print.
Subsequently, the RDD[(K,V)] is converted into SubtractedRDD
, map(...) is being used hence resultant RDD will have None Partitioner.
Before concluding , I would like to share a piece of source code which I consider as an essence of this article.
val rdd1 = spark.sparkContext.parallelize(Seq(("1", 1), ("1", 2), ("3", 3)
, ("3", 4), ("1", 5), ("7", 7)))
val rdd2 = spark.sparkContext.parallelize(Seq(("1", 1), ("1", 2), ("3", 3)
,("3", 4), ("1", 5)))
val result = rdd1.subtract(rdd2, new HashPartitioner(2))
println(result.partitioner)
result.foreach(println(_))
Result
None (7,7)DAG

subtract(RDDFrom the method signature and DAG, it is clear that subtract(...) is a wide operation.other) subtract(RDD other, Partitioner p, scala.math.Ordering ord) subtract(RDD other, int numPartitions)
As you already know that you can apply partitioner only on RDD[(K,V)], hence this transformation is required. It converts given RDD[T] into RDD[(K,V)] where K is T and V will be always null. The outcome of this transformation is subtract block in both stage0 and stage1 on DAG screen-print.
Subsequently, the RDD[(K,V)] is converted into SubtractedRDD
map(???).subtractByKey(???).map(???)It is important to note that, resultant RDD of subtract() will not have any Partitioner even though if both RDD1 and RDD2 had Partitioners. Reason is, to extract keys from SubtractedRDD
Before concluding , I would like to share a piece of source code which I consider as an essence of this article.
this.map(x => (x, null)).subtractByKey(other.map((_, null)), p2).keys
Comments
Post a Comment