Intersection()
RDD's intersection() operation is equivalent to SQL's intersect operation and one of the three primary set operation and it is slightly in contrast with subtract() operation in general. It compares two RDDs and returns a new RDD with records present in both rdd1 and rdd2. It is important to note that the resultant RDD will not contain any duplicates even if the input RDDs did. For better understanding, let's start with an example
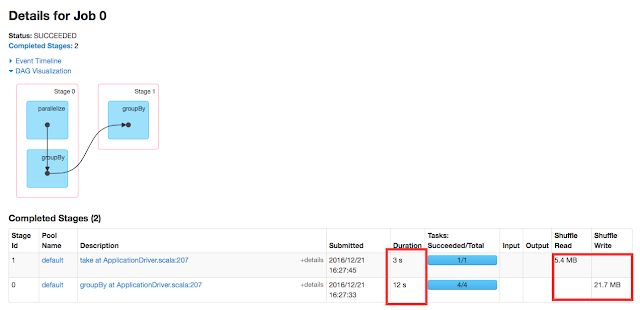
DAG

Intersection is a wide operation in RDD. RDD[T] provides 3 variants of operation in terms of method signature and let's see them briefly
val rdd1 = spark.sparkContext.parallelize(Seq(("1", 1), ("1", 2), ("1", 2),
("3", 3), ("3", 4), ("1", 5), ("7", 7)))
val rdd2 = spark.sparkContext.parallelize(Seq(("1", 1), ("1", 1), ("1", 2),
("3", 3), ("3", 4), ("1", 5)))
rdd1.intersection(rdd2).foreach(println(_))
Result(1,5) (1,1) (1,2) (3,3) (3,4)
DAG

Intersection is a wide operation in RDD. RDD[T] provides 3 variants of operation in terms of method signature and let's see them briefly
intersection(RDDThis variant takes Partitioner as an argument and it applies during cogroup() internally.The method documentation says, Partitioner to use for the resulting RDD. In the contrary, the resultant rdd has None partitioner and the version I'm using for this article is 2.4.0other, Partitioner partitioner,scala.math.Ordering ord)
val result = rdd1.intersection(rdd2, new HashPartitioner(2)) println(result.partitioner) result.foreach(println(_))
Result
None (1,5) (1,2) (1,1) (3,4) (3,3)
intersection(RDDThis variant takes just partition number and it applies HashPartitioner internally by default and resultant rdd will have None partitioner.other, int numPartitions)
intersection(RDDother)
The last variant dose't required partition details neither it applies internally.
Now let's dig deeper into the internals of the operation.In the core, all three variants transforms input RDDs into RDD[(K,V)] and the same can be seen in intersection block in both stage0 and stage1. Subsequently, rdd1 and rdd2 are transformed as CoGroupedRDD using cogroup() which can been seen as first dot in stage2 .Later input rdd is transformed into RDD[(K,V)] that is specified as second dot in stage2. Then it filters records of CoGroupedRDD which has both left and right group which specifies third dot in stage2. Finally keys are extracted and returned as resultant RDD. Find the source code of one the variant
this.map(v => (v, null)).cogroup(other.map(v => (v, null))) .filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }.keys
It is important be note, neither of the intersection() variant's resultant RDD will have Partitioner even if the input RDDs did.
Comments
Post a Comment